

Case Study
Building the Brand Identity Estimator
Brand identity work is notoriously hard to quote, scope can span a single logo brief to a 300-page brand bible, and the difference between a clear-vision client and a stakeholder-heavy organization can double the actual hours delivered. This tool applies a COCOMO-inspired PERT model to brand identity estimation: 26 brand bible sections mapped to complexity points, four EAF drivers, named tier packages, and a self-calibrating coefficient that improves with every completed project. It runs as a zero-dependency HTML file, a Node.js CLI, and a Python CLI; all sharing identical model logic.
Background & Context
Brand identity projects resist clean scoping because the deliverable is inherently qualitative. A logo system and a full brand bible can both be called "brand work," but they occupy completely different quadrants of effort and expertise. Clients rarely arrive knowing what tier of service they need, and designers rarely have a structured way to communicate what they're actually selling.
Most brand freelancers quote from memory, averaging past projects and adjusting for gut feel. This works until a client asks for a line-item breakdown, or until a project runs long and there's no model to explain why. The problem isn't that estimating is hard; it's that there's been no established formal model for brand-specific work the way COCOMO and function-point analysis serve software engineering.
The Brand Identity Estimator fills that gap. It borrows the architecture of the Freelance Project Cost Estimator, same formula structure, same calibration loop, and regrounds it entirely in brand work: brand strategy, visual identity, typography systems, voice and tone, motion guidelines, accessibility standards, and everything in between.
Problem Statement
The Question: How do you produce a defensible, line-item brand identity quote before the engagement begins and explain it to a client without a spreadsheet?
The Problem: Brand work involves radically different effort levels depending on which sections of the brand system are in scope. Quoting a "full brand package" without specifying exactly what that means leads to scope creep, under-delivery, or renegotiation after kickoff.
The Challenge: The 26-section brand bible structure has to be usable by someone who isn't a project manager. Clients need to understand what they're selecting. Designers need to be able to walk through it on a call. And the model has to remain defensible even when vision clarity is low and stakeholder complexity is high.
Methodology / Approach
The model runs in four stages:
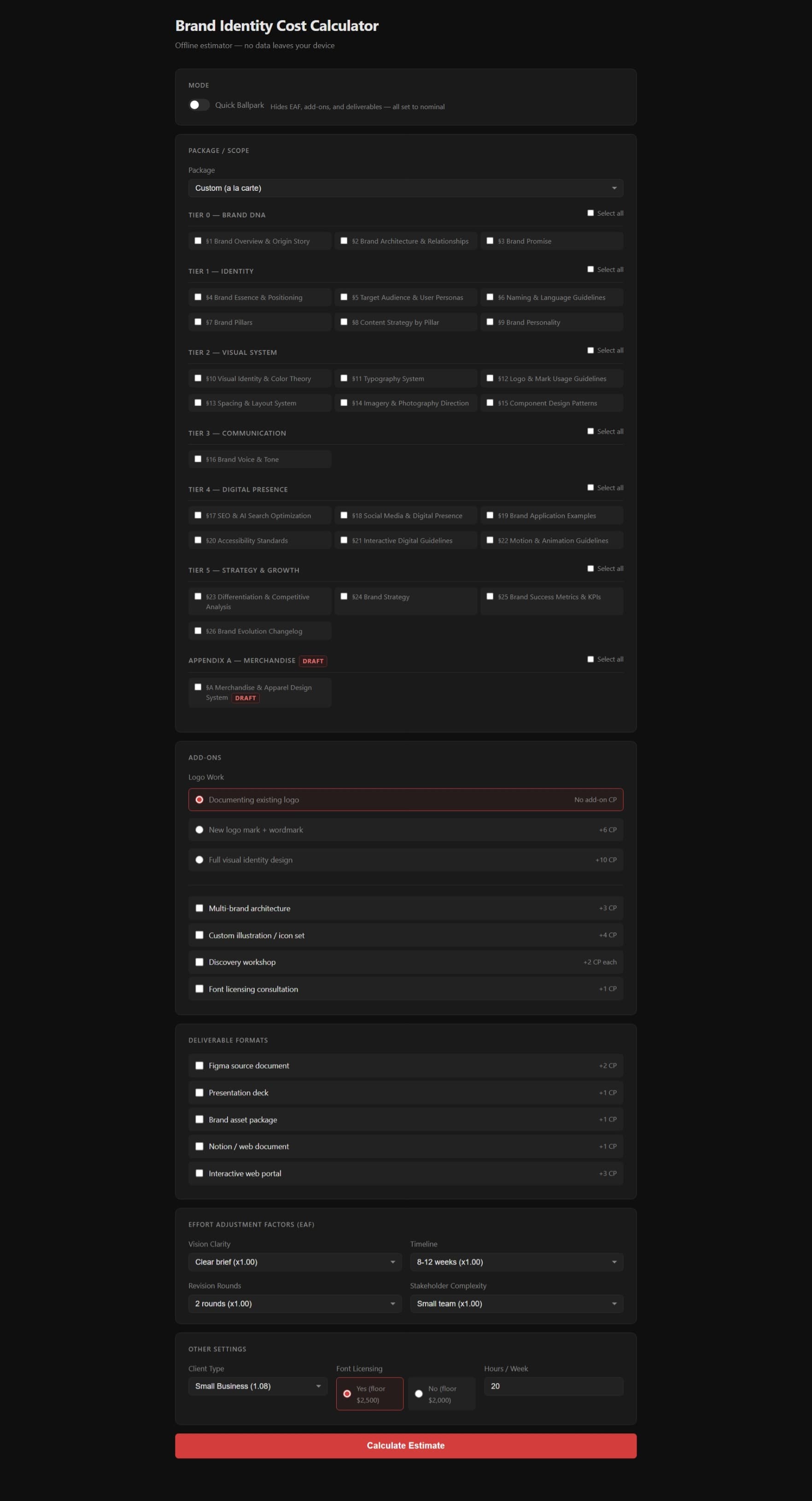
Complexity Points (CP): Each of the 26 brand bible sections and Appendix A carries a fixed CP value (1–5) derived from estimated research, iteration, and delivery effort. Sections are grouped into six tiers, foundational strategy through advanced differentiation, plus an appendix for merchandise and apparel systems. A named package (Starter, Basic, Comprehensive, Digital Complete, Full Identity System) sets a predetermined section selection with a 7% discount applied to the resulting estimate.
Effort Adjustment Factor (EAF): Four independent multipliers compound to produce the EAF: vision clarity (×0.85-1.40), timeline pressure (×0.90-1.45), revision rounds (×0.90-1.35), and stakeholder complexity (×0.90-1.40). A client with crystal-clear brand vision, a relaxed timeline, agreed revision limits, and a single decision-maker can push the EAF to 0.65; a client with a vague brief, a rushed deadline, unlimited rounds, and a committee of stakeholders can push it past 2.85×.
PERT three-point range: Optimistic (×0.75), most likely (×1.0), and pessimistic (×1.55) multipliers feed a PERT formula, producing an expected effort
Eand standard deviation. The resulting hour range is priced at 180/hr, with a quote floor of $2,500 (with licensed fonts) or $2,000 (without).Line-item breakdown: Each selected section is individually priced at both rate endpoints, producing a section-level cost table the designer can share directly or use as a proposal appendix.
Analysis and Findings
Section CP values required real calibration. An initial draft assigned CP based on deliverable complexity alone, treating "Brand Strategy" as simply more pages than "Brand Promise." Actual project review showed that some high-page sections (Visual Identity & Color Theory) require fewer net hours than conceptually lighter ones (Brand Voice & Tone) because voice and tone work involves more iteration and client co-creation. The CP table went through two significant revisions before stabilizing.
Stakeholder complexity is the most underweighted EAF driver in brand work. In software estimation models, the equivalent driver is usually organizational complexity or team size. For brand projects, it's almost always stakeholder dynamics, a single founder makes decisions quickly; a marketing committee reviews deliverables by committee, delays feedback, and often reverses decisions after approval. Capping the stakeholder multiplier at ×1.40 without a higher ceiling was a deliberate conservative choice, not because 1.40 is a ceiling in practice, but because anything above it signals a scope renegotiation conversation rather than a multiplier adjustment.
Named packages create anchoring. Before introducing the package tier system, most test users selected sections one at a time and consistently under-selected, treating each checkbox as an optional add-on rather than part of a coherent system. Named packages (Starter, Basic, Comprehensive, etc.) shifted the interaction clients start from a recognized tier and add or remove rather than building from nothing. This behavioral change alone improved estimate completeness in informal testing.
Solutions and Implementation
Browser Calculator
brand-calculator.html is a self-contained HTML file with no external dependencies; no CDN, no framework, and no build step. Sections are presented in tier groups with "select all" toggles per tier. The EAF drivers are four-option selects with plain-language descriptions of each level. The estimate panel updates in real time as sections are checked or unchecked. The file is designed for a scoping call: download once, open in any browser, share the screen, and walk through it with the client.
Conclusion and Lessons Learned
The hardest part of building this tool was resisting the urge to make it universally applicable. Brand work at a small agency, a solo freelancer, and an in-house team have meaningfully different effort profiles; rates, revision norms, and stakeholder structures. The model is deliberately calibrated for solo freelance work at the 180/hr range. Making it more general would require either more inputs (which breaks the scoping-call use case) or less accuracy (which defeats the purpose).
The deeper lesson is that the value of the model isn't just precision, it's structure. A brand project that scores high on stakeholder complexity and low on vision clarity is going to be hard regardless of the hour estimate. The EAF makes that visible at the start of the engagement, before the designer has committed to a price. That conversation, "your EAF is 1.85, which means this engagement has meaningful execution risk", is worth more than the number itself.
Project README
brand-estimator
Freelance brand identity project cost estimator. COCOMO-inspired PERT model with
section-level à la carte pricing across 26 brand bible sections + Appendix A.
Quick Start
Node.js CLI
node brand-estimate.js
Python CLI
python brand_estimate.py
HTML Calculator
Open brand-calculator.html in any browser — no server required.
Model
Scope CP → H_base = COEFF_A × CP^EXP_B → EAF → PERT → cost range + line-item breakdown.
- COEFF_A = 1.5 (default, self-calibrating after 5+ logged projects)
- MIN_RATE = $75/hr | MAX_RATE = $180/hr
- Quote floor: $2,500 with licensed fonts, $2,000 without
- Named package discount: 7%
Section CP Reference
| # | Section | Tier | CP |
|---|---|---|---|
| 1 | Brand Overview & Origin Story | 0 | 1 |
| 2 | Brand Architecture & Relationships | 0 | 1 |
| 3 | Brand Promise | 0 | 1 |
| 4 | Brand Essence & Positioning | 1 | 2 |
| 5 | Target Audience & User Personas | 1 | 3 |
| 6 | Naming & Language Guidelines | 1 | 1 |
| 7 | Brand Pillars | 1 | 1 |
| 8 | Content Strategy by Pillar | 1 | 1 |
| 9 | Brand Personality | 1 | 1 |
| 10 | Visual Identity & Color Theory | 2 | 3 |
| 11 | Typography System | 2 | 2 |
| 12 | Logo & Mark Usage Guidelines | 2 | 3 |
| 13 | Spacing & Layout System | 2 | 1 |
| 14 | Imagery & Photography Direction | 2 | 2 |
| 15 | Component Design Patterns | 2 | 2 |
| 16 | Brand Voice & Tone | 3 | 4 |
| 17 | SEO & AI Search Optimization | 4 | 2 |
| 18 | Social Media & Digital Presence | 4 | 2 |
| 19 | Brand Application Examples | 4 | 2 |
| 20 | Accessibility Standards | 4 | 1 |
| 21 | Interactive Digital Guidelines | 4 | 1 |
| 22 | Motion & Animation Guidelines | 4 | 2 |
| 23 | Differentiation & Competitive Analysis | 5 | 2 |
| 24 | Brand Strategy | 5 | 3 |
| 25 | Brand Success Metrics & KPIs | 5 | 1 |
| 26 | Brand Evolution Changelog | 5 | 1 |
| A | Merchandise & Apparel Design System | Appendix | 5 |
Named Packages
| Package | Sections | CP |
|---|---|---|
| Starter | §1–3, §10–12 | 11 |
| Basic | Tiers 0–2 (§1–15) | 25 |
| Comprehensive | Tiers 0–3 (§1–16) | 29 |
| Digital Complete | Tiers 0–4 (§1–22) | 39 |
| Full Identity System | All + Appendix A | 51 |
EAF Drivers
| Driver | Level 1 | Level 2 | Level 3 | Level 4 |
|---|---|---|---|---|
| Vision clarity | ×0.85 | ×1.00 | ×1.20 | ×1.40 |
| Timeline | ×0.90 | ×1.00 | ×1.20 | ×1.45 |
| Revision rounds | ×0.90 | ×1.00 | ×1.15 | ×1.35 |
| Stakeholder complexity | ×0.90 | ×1.00 | ×1.20 | ×1.40 |
Tests
# Node.js
node --test tests/brand-model.test.js
node --test tests/estimate.test.js
# Python
python -m pytest tests/test_brand_estimate.py -v
Calibration
Log actual hours after completing a project to improve COEFF_A over time.
node brand-estimate.js --calibrate
python brand_estimate.py --calibrate
The model automatically uses the calibrated COEFF_A once 5+ projects are logged.
Calibration data is stored in data/calibration.csv.
Claude Code Skill
This repo is the standalone scripts companion to the /brand-project Claude Code skill
(~/.agents/skills/brand-project/SKILL.md). The skill and CLI share identical model
logic — same constants, same formula, same output format.
Project Gallery
This album serves as a portfolio gallery for my Brand Estimator.